CloudWatch Logsのサブスクリプションフィルターを利用してData Firehose経由でS3にログを保存する構成はよく採用されるパターンだと思う。
しかしデフォルト状態だとログデータがFirehoseを経由する際に改行区切りのない1行のJSON文字列としてS3に保存され、そのままではAthenaから扱うのが難しい。
以前はこの問題に対処するためLambda関数を使ってレコード変換し、改行を入れるなど分析しやすいフォーマットに変換するのがセオリーだったと記憶していて、そういうLambda Blueprintも用意されていた気がする(記憶違いの可能性あり)。
今回S3の特定のパスにいろんなログをぶち込んでロググループ単位でAthenaでフィルタできるようにしたいことがあった。
しかし記憶の中のBlueprintが見当たらず、自分でLambda書くしかないのかなということで少し面倒な気持ちになっていたが、結論ノーコードで実現できたので方法をメモしておく。
なおこの方法が令和何年からできたのかは確認しておらず不明です。雑なタイトルですみません。
結論
対象Firehoseストリームで以下の通り設定する。
Amazon CloudWatch Logs からソースレコードを解凍する: オン
改行の区切り文字: 有効
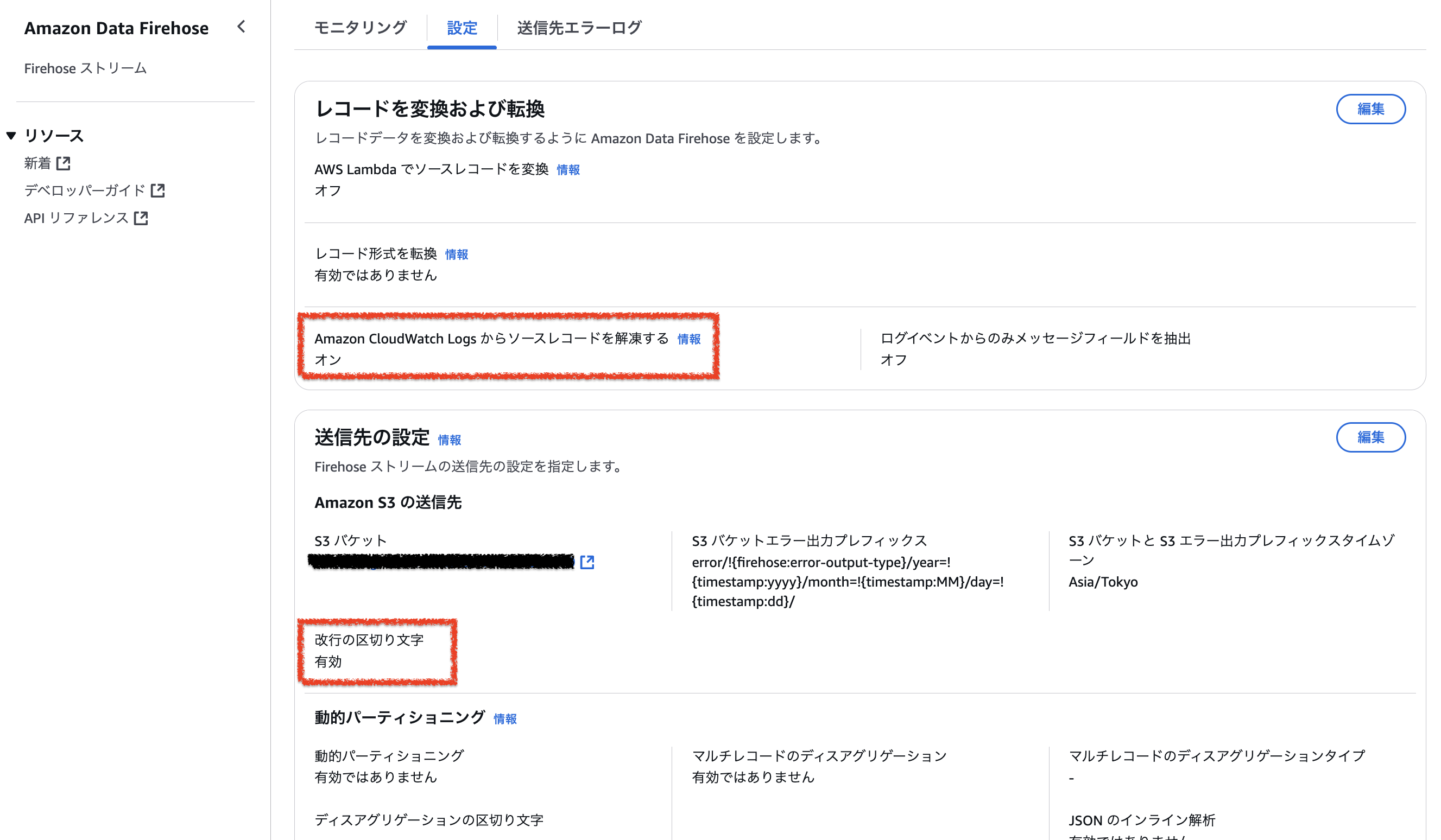
この設定によりCloudWatch Logsから送信されるgzip圧縮されたログが自動的に解凍され各ログイベントに改行が追加される。
もう少し手の込んだことをしたければLambdaが必要になるが、とりあえず雑にAthenaから参照できればよいならこれで十分である。
なおデータレコードの圧縮設定を有効にしておけば、S3に保存されるファイルは指定の形式で圧縮された状態となる。
参考までにこの設定をしたFirehoseストリームを作成するTerraformテンプレート例を書いておく。
processing_configurationブロックがポイントとなる。
resource "aws_kinesis_firehose_delivery_stream" "cloudwatch_logs_to_s3" {
destination = "extended_s3"
name = "cloudwatch-logs-to-s3"
extended_s3_configuration {
bucket_arn = "<保存先のS3バケットARN>"
buffering_interval = 300
buffering_size = 5
compression_format = "GZIP"
custom_time_zone = "Asia/Tokyo"
error_output_prefix = "error/!{firehose:error-output-type}/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/"
prefix = "logs/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/"
role_arn = "<firehoseストリームに設定するIAMロールARN>"
cloudwatch_logging_options {
enabled = true
log_group_name = "/aws/kinesisfirehose/cloudwatch-logs-to-s3"
log_stream_name = "DestinationDelivery"
}
processing_configuration {
enabled = true
processors {
type = "Decompression"
parameters {
parameter_name = "CompressionFormat"
parameter_value = "GZIP"
}
}
processors {
type = "AppendDelimiterToRecord"
}
}
}
}